高效学习(二):怎样高效记忆并快速调用知识

那么,如何才能高效地记忆并快速调用文章中的考点呢?
我们给出的答案是: 掌握形式逻辑的基础知识, 运用“逻辑树”记住文章的重要内容(泽宇GMAT阅读法)。 人在记忆的过程中主要是通过“联想(associate)”来记住新的事物和知识的, 而文章的逻辑树就是帮助大家联想记忆文章内容的关键。这个处理解读文章的过程,就是一个chunking的过程。
当我们学习新的知识时,大脑会面临很辛苦的认知负担(Cognitive load),大脑需要一个过程去理解、消化这些内容,并把他们组合在一起的过程就叫Chunking。如果我们只是简单的、被动的去学习一个新知识,而不是尝试把它与其它已掌握的知识结合、联系起来,你就无法很好的使用它。这里有一个很形象的例子,我们拼图的过程就可以比作一个chunking的过程,一块块的拼图版块就是一个个的mini chunks,不把它们拼凑成一张完整的图画,这堆零散的chunks就毫无意义。

比如,我们来一起读下面这段文章:
“Caffeine, the stimulant in coffee, has been called “the most widely used psychoactive substance on Earth.” Snyder, Daly and Bruns have recently proposed that caffeine affect behavior by countering the activity in the human brain of a naturally occurring chemical called adenosine. Adenosine normally depresses neuron firing in many areas of the brain. It apparently does this by inhibiting the release of neurotransmitters, chemicals that carry nerve impulses from one neuron to the next. Like many other agents that affect neuron firing, adenosine must first bind to specific receptors on neuronal membranes. There are at least two classes of these receptors, which have been designated A1 and A2. Snyder et al propose that caffeine, which is structurally similar to adenosine, is able to bind to both types of receptors, which prevents adenosine from attaching there and allows the neurons to fire more readily than they otherwise would.”
我们利用“逻辑树”来整理一下文章的线索脉络:
Caffeine = CA
Adenosine= AD
Neuron Firing = NF
因为CA抑制AD, AD 又抑制NF
所以 CA 加强 NF (负负得正),即Caffeine is a stimulant
具体原因:
AD 通过绑定 A1+A2 后抑制NF
CA 跟AD 结构相似 , 绑定A1+A2 后阻止 AD绑定A1+A2, 所以可以加强NF
掌握了这个逻辑树,本段的绝大部分内容自然清晰的记忆在大家的头脑中了 。
神经科学家认为Chunking的本质就是通过意义的联系和重复的使用而形成神经回路,而回路中的其他相关神经元也会被同时激活,使得我们在回忆一个知识点或者在执行一个操作的时候能更容易。建立良好的Chunking能让我们更好的调用知识,也能让我们把已经学过的知识融入到一个完整的逻辑体系中。
求败单词通就正是基于此理论设计出来帮助大家把单词做成chunks来记忆。我们先利用一个简单词比如husband(丈夫)来推出词根,-band- (连接,边界)(毕竟丈夫就是和妻子有连接的人)。然后学习和这个词根相关的高级词,例如abandon= a(前缀,表否定)+band(连接)+on(后缀,表动作持续) -> 不再连接因此放弃

是不是突然发现,记忆abandon,abound, abundant 这几个词容易了很多?
那怎样在学习时才能把知识组合成块(chunk)呢?
首先,我们要运用专注模式(Focus mode),集中精力去学习、理解知识。科学家比喻说,当我们头脑在建立chunk的时候,工作记忆就好像一条只有四只脚的章鱼在头脑中努力建立神经连接一样,分心会占用四条腿,使得chunk难以形成。
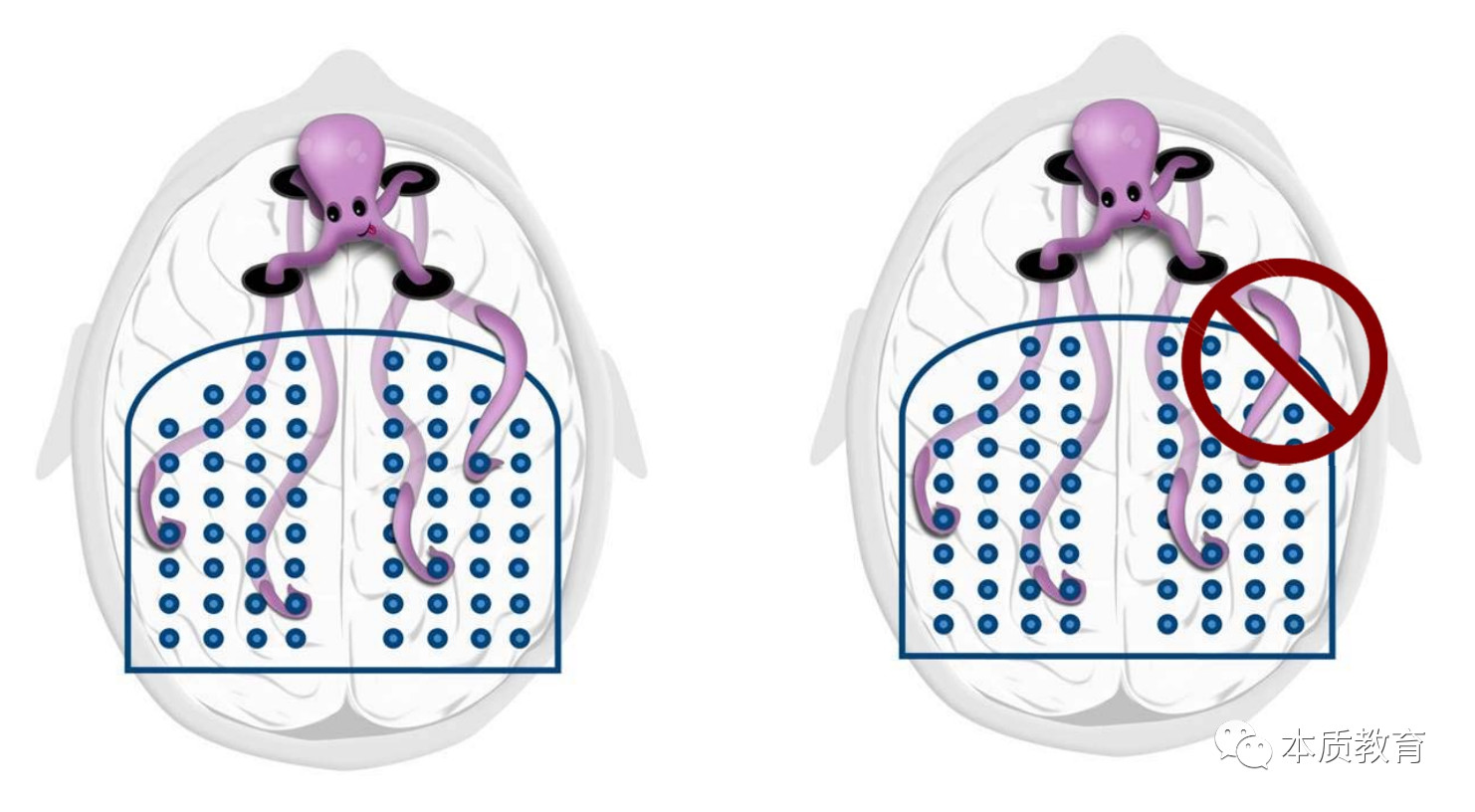
这也就是我们常说的“集中突破法”背后的本质。如果人脑无法专心在同一个知识点上,那么就很难建立chunk,从而难以很好的掌握这个知识。所以,我们总是建议学生集中一段时间来学习、复习同一门学科,当完全掌握了这个知识点、这个学科后,再move on到下一个。不少GMAT的考生会问我们怎样安排复习时间,我们的建议是,比如这周末上了阅读课,那么在下一周内就集中使用泽宇老师的阅读法去练习阅读,直到全部做对为止。又比如,我们最近展开的“高考数学140+学霸孵化突破训练营”就是根据“集中突破法”组织学生一起集中火力,在泽宇的带领下攻克一个专题下所有相关的高考数学题目。
第二,理解Understand。
理解的过程,就像是用胶水把chunk之间联系起来(如下图中不同颜色的闭环被相互联系到一起),使得知识更容易被调用。
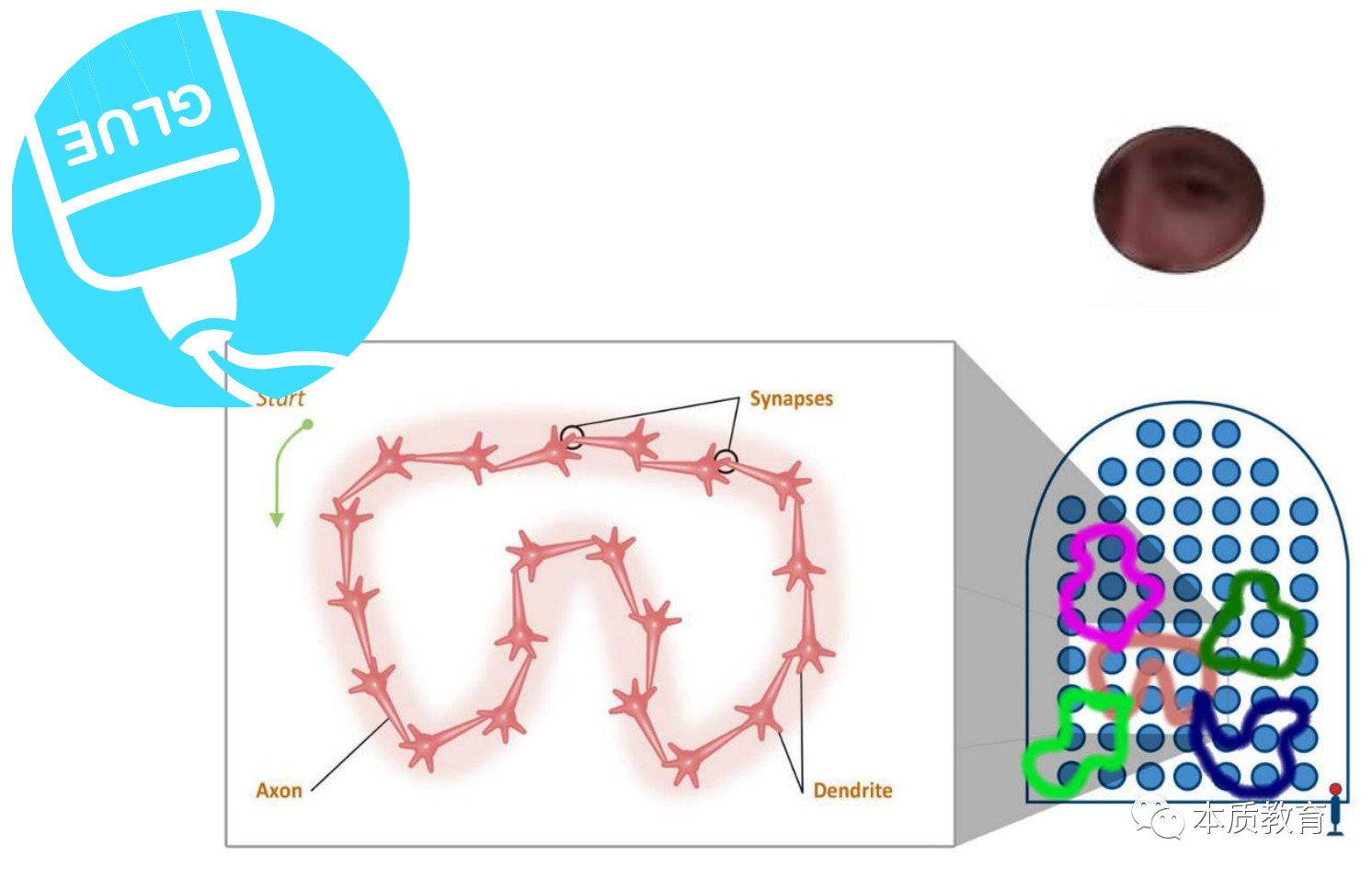
这就解释了死记硬背的弊端。遇到见过的、背过的习题,他能搞定,但是当问题稍微变通或者遇到全新的题目时,他就傻眼了。因为他最初记忆的时候根本没有深入理解知识,在他眼中,解题过程其实和背诵诗词没有什么区别。我刚好在网上看到一个学生说自己研究过数千道导数压轴题,脑海里储存了500多道高难度的导数压轴题,却仍然觉得2015年四川高考数学压轴题难于上青天。
然而,对于理解记忆的人来说,知识中包含了精准透彻的概念、逻辑、背景知识、解题的思维与策略等等内容,而不是某段孤立的、零散的片段。而且,知理解记忆的另一个重要好处是,即使已经忘记其他细节也可以自己推导出来,无需费力记忆。有一个广为流传的段子,说的是数学家David Hilbert的一个故事:一次在Hilbert的讨论班上,一个年轻人做报告用了一个很美的定理,Hilbert说“这真是一个妙不可言的定理呀,是谁发现的?”那个年轻人茫然的站了很久,对 Hilbert说:“是你……”(求这位学生的心理阴影面积)

最后,就是要“刻意练习”Practice,从而建立上下文背景Context。
纸上得来终觉浅,绝知此事要躬行。通过反复练习可以把知识点逐个掌握,这是所谓从底向上(Bottom-up)的学习方式,而要宏观了解所学科目的 宏图框架Big Picture就需要从上往下(Bottom-down)的学习,这两种方法的重合点就是 上下文Context。
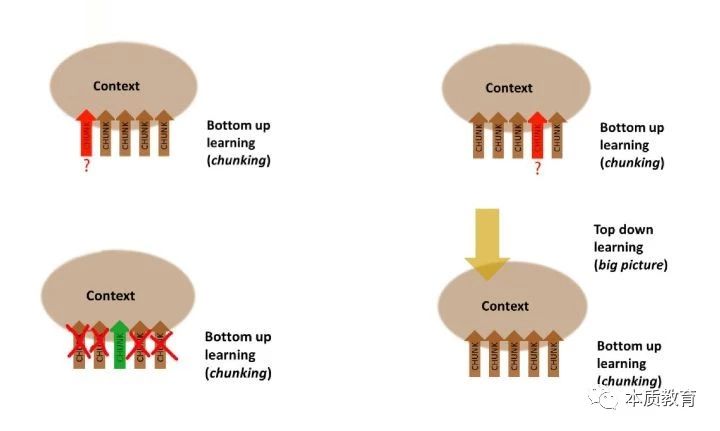
一旦建立上下文背景线索, 你就能够知道在什么时候该使用哪个 Chunk,而不该使用哪一个以及你会清楚明了每个chunk在整个知识体系中的位置。缺乏线索的记忆就像孤岛,看得见摸不着,而具备线索的记忆则是罗马,条条道路都可以抵达。
